

Lead Image: This illustration depicts NASA’s Mars 2020 rover studying rocks with its robotic arm. Credit: NASA/JPL-Caltech
The findings by rover scientists highlight the diversity of samples geologists and future scientists associated with the agency’s Mars Sample Return program will have to study.
Scientists with NASA’s Perseverance Mars rover mission have discovered that the bedrock their six-wheeled explorer has been driving on since landing in February likely formed from red-hot magma. The discovery has implications for understanding and accurately dating critical events in the history of Jezero Crater – as well as the rest of the planet.
The team has also concluded that rocks in the crater have interacted with water multiple times over the eons and that some contain organic molecules.
These and other findings were presented on December 15, 2021, during a news briefing at the American Geophysical Union fall science meeting in New Orleans.
Taken by Perseverance’s Mastcam-Z instrument, this video features an enhanced-color composite image that pans across Jezero Crater’s delta on Mars. The delta formed billions of years ago from sediment an ancient river carried to the mouth of a lake that once existed in the crater. Credit: NASA/JPL-Caltech/ASU/MSSS
Even before Perseverance touched down on Mars, the mission’s science team had wondered about the origin of the rocks in the area. Were they sedimentary – the compressed accumulation of mineral particles possibly carried to the location by an ancient river system? Or where they igneous, possibly born in lava flows rising to the surface from a now long-extinct Martian volcano?
“I was beginning to despair we would never find the answer,” said Perseverance Project Scientist Ken Farley of Caltech in Pasadena. “But then our PIXL instrument got a good look at the abraded patch of a rock from the area nicknamed ‘South Séítah,’ and it all became clear: The crystals within the rock provided the smoking gun.”
The drill at the end of Perseverance’s robotic arm can abrade, or grind, rock surfaces to allow other instruments, such as PIXL, to study them. Short for Planetary Instrument for X-ray Lithochemistry, PIXL uses X-ray fluorescence to map the elemental composition of rocks. On Nov. 12, PIXL analyzed a South Séítah rock the science team had chosen to take a core sample from using the rover’s drill. The PIXL data showed the rock, nicknamed “Brac,” to be composed of an unusual abundance of large olivine crystals engulfed in pyroxene crystals.
“A good geology student will tell you that such a texture indicates the rock formed when crystals grew and settled in a slowly cooling magma – for example a thick lava flow, lava lake, or magma chamber,” said Farley. “The rock was then altered by water several times, making it a treasure trove that will allow future scientists to date events in Jezero, better understand the period in which water was more common on its surface, and reveal the early history of the planet. Mars Sample Return is going to have great stuff to choose from!”

The multi-mission Mars Sample Return campaign began with Perseverance, which is collecting Martian rock samples in search of ancient microscopic life. Of Perseverance’s 43 sample tubes, six have been sealed to date – four with rock cores, one with Martian atmosphere, and one that contained “witness” material to observe any contamination the rover might have brought from Earth. Mars Sample Return seeks to bring select tubes back to Earth, where generations of scientists will be able to study them with powerful lab equipment far too large to send to Mars.
Still to be determined is whether the olivine-rich rock formed in a thick lava lake cooling on the surface or in a subterranean chamber that was later exposed by erosion.
Organic Molecules
Also great news for Mars Sample Return is the discovery of organic compounds by the SHERLOC (Scanning Habitable Environments with Raman & Luminescence for Organics & Chemicals) instrument. The carbon-containing molecules are not only in the interiors of abraded rocks SHERLOC analyzed, but in the dust on non-abraded rock.
Confirmation of organics is not a confirmation that life once existed in Jezero and left telltale signs (biosignatures). There are both biological and non-biological mechanisms that create organics.
“Curiosity also discovered organics at its landing site within Gale Crater,” said Luther Beegle, SHERLOC principal investigator at NASA’s Jet Propulsion Laboratory in Southern California. “What SHERLOC adds to the story is its capability to map the spatial distribution of organics inside rocks and relate those organics to minerals found there. This helps us understand the environment in which the organics formed. More analysis needs to be done to determine the method of production for the identified organics.”
The preservation of organics inside ancient rocks – regardless of origin – at both Gale and Jezero Craters does mean that potential biosignatures (signs of life, whether past or present) could be preserved, too. “This is a question that may not be solved until the samples are returned to Earth, but the preservation of organics is very exciting. When these samples are returned to Earth, they will be a source of scientific inquiry and discovery for many years,” Beegle said.
‘Radargram’
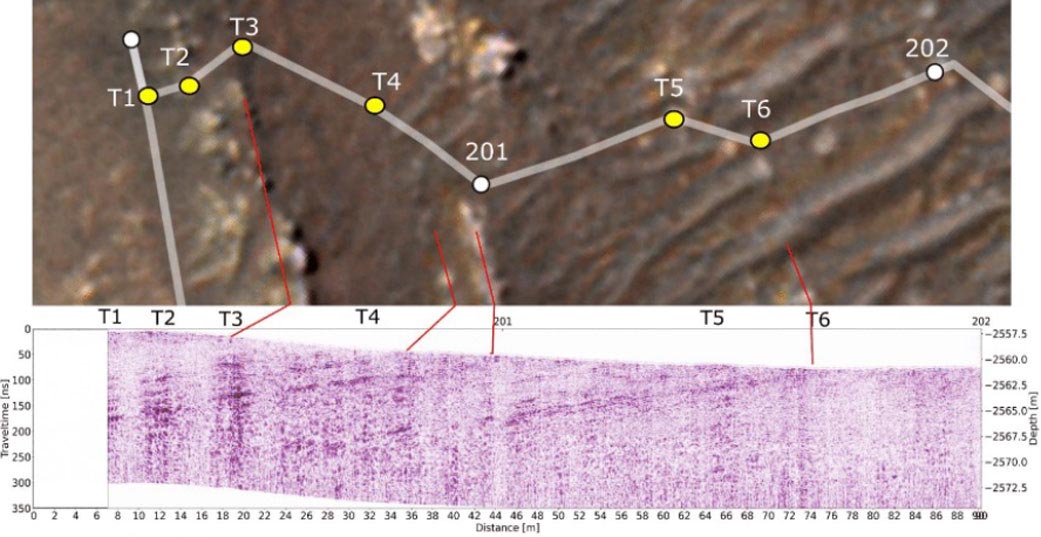
Along with its rock-core sampling capabilities, Perseverance has brought the first ground-penetrating radar to the surface of Mars. RIMFAX (Radar Imager for Mars’ Subsurface Experiment) creates a “radargram” of subsurface features up to about 33 feet (10 meters) deep. Data for this first released radargram was collected as the rover drove across a ridgeline from the “Crater Floor Fractured Rough” geologic unit into the Séítah geologic unit.
The ridgeline has multiple rock formations with a visible downward tilt. With RIMFAX data, Perseverance scientists now know that these angled rock layers continue at the same angle well below the surface. The radargram also shows the Séítah rock layers project below those of Crater Floor Fractured Rough. The results further confirm the science team’s belief that the creation of Séítah preceded Crater Floor Fractured Rough. The ability to observe geologic features even below the surface adds a new dimension to the team’s geologic mapping capabilities at Mars.
More About Perseverance
A key objective for Perseverance’s mission on Mars is astrobiology, including the search for signs of ancient microbial life. The rover will characterize the planet’s geology and past climate, pave the way for human exploration of the Red Planet, and be the first mission to collect and cache Martian rock and regolith (broken rock and dust).
Subsequent NASA missions, in cooperation with ESA (European Space Agency), would send spacecraft to Mars to collect these sealed samples from the surface and return them to Earth for in-depth analysis.
The Mars 2020 Perseverance mission is part of NASA’s Moon to Mars exploration approach, which includes Artemis missions to the Moon that will help prepare for human exploration of the Red Planet.
JPL, which is managed for NASA by Caltech in Pasadena, California, built and manages operations of the Perseverance rover.




